在现在大数据、高并发,到处都充斥着流量的互联网时代,能不能应对高并发俨然已经发展成一个衡量服务端架构是否合格的标准,作为程序媛我们思考如何利用语言在代码层面最优设计能应对并发的程序去并行处理任务。在程序中对于任务并行处理一般趋于使用:进程、线程,以及另外一种:协程。支持协程的语言有很多,比如:C/C++、Ruby、 Python(2.5+)、Golang等等,它们有些是本身语言支持协程,有些则是需要引入第三方包来使用。不过,我们主要来学习一下Golang这门语言(简称Go),它是如何理解以及实现协程的。
一、进程、线程和协程的前世今生
都知道一台计算机的核心是CPU,它承担着所有的运算。而计算机承载的操作系统(内核)则是负责所有任务的处理和调度CPU以及资源的分配。如果用人类来比喻,大脑是CPU,思维则是操作系统(内核)。
进程
最早的计算机每次只能运行一个程序,如果还有其他程序需要执行则要排队等待。后来CPU运算能力提高了,这种方式过于原始有些浪费性能,于是尝试让多个程序可以并行执行,但是这样面临一个新的问题:跑在同一个CPU中的程序都会使用计算机资源,那程序的运行状态和数据怎么保障?进程。
1 | 进程是内核资源管理分配的最小单位,每个进程都有独立的虚拟地址空间。内核中的每个程序都运行在独立进程的上下文中,上下文是由程序正常运行需要的一系列参数组成,参数包括存储器中的代码和数据,寄存器中的内容以及进程打开的文件描述符(文件句柄)等。可以把上下文通俗理解为:`环境`。 |
如果程序在运行过程中需要进行IO操作,IO操作阻塞了程序后面的计算,这时候CPU属于空闲状态,那内核会把CPU切换到其他进程去处理。不过当进程数量变高以后,计算机的大部分资源都被进程切换这个操作消耗掉了。为什么说进程切换操作消耗资源代价比较高?
1 | 所谓进程切换其实就是上下文切换,需要切换新的页表并加载新的虚拟地址空间、切换内核栈以及硬件上下文等。只要发生进程切换操作就得反复进入内核,加载切换一系列状态。 |
线程
为了减少这种开销,线程应运而生。
1 | 线程是内核调度CPU执行的最小单位,线程是运行在进程上下文的逻辑流,线程是具体执行程序的单位。一个进程至少包含一个主线程(可以拥有多个子线程),但是一个线程只能存在于一个进程中。 |
线程切换相比进程切换开销就小了很多,线程切换只需要把寄存器刷新即可。
协程
后面程序媛们发现线程这样还是有性能瓶颈(IO阻塞),无论是进程还是线程因为涉及到大量的计算机资源,所以都是由内核调度管理。能不能开发一种由代码控制的线程呢?这就是协程。
1 | 协程是由用户控制的线程(用户态线程),协程在程序中实现自我调度,不需要像进程切换一样进入内核加载切换状态,提高了线程在IO上的性能问题(IO多路复用)。 |
但是协程也有个致命的问题,假如进程中的某一程序出现了阻塞操作同时被CPU中断处理(抢占式调度),那么该进程中的所有线程都会被阻塞。
后面会专门写一篇关于进程和线程以及协程的特性以及区别。(不够详细,埋坑Orz~)
二、什么是goroutine?
上面简单学习了进程和线程以及协程的渊源,虽然不够详细但是我们大概知道其实在进程或者线程甚至于协程存在的性能瓶颈大部分是CPU调度问题。
1 | go func() // Go语言启动协程,只需要使用go关键字即可启动协程运行函数。使用go关键字创建的这个协程就叫做`goroutine` |
之前说了goroutine是Go语言的协程,其实这么理解是可以的但goroutine比协程更强大。它们使用的线程模型有着本质的区别,如下:
goroutine通过通道来通信,而协程通过让出执行和恢复操作来通信。
goroutine通过Go语言的调度器进行调度,而协程通过程序本身调度。
大部分语言或者第三方库提供的协程就是使用的用户态线程模型,但goroutine使用的不是传统的用户态线程模型。以下主流的线程模型:
- 内核级线程模型
内核级别的线程的状态切换需要内核直接处理,所以内核清楚的知道每一个KSE(Kernel Scheduling Entity)的存在(即内核线程和KSE是一对一关系),它们可以全系统内进行资源的竞争。 - 用户级线程模型(用户态线程,协程)
用户态级别的线程受用户控制,内核并不直接知道用户态线程的存在(为什么这么说?因为用户态线程和内核线程存在着多对一的关系,即多个用户态线程对应一个内核线程),一般用户态多线程属于同一个进程,所以它们只能在进程内进行资源竞争。 - 两级线程模型(混合型线程模型)
两级线程模型吸取了内核级和用户级线程的经验,两级线程模型下的线程和内核线程处于多对多的关系。一个进程内的多个线程可以分别绑定内核线程,既可以多个线程绑定多个内核线程也可以多个线程绑定一个内核线程,当某个线程内的程序产生阻塞其绑定的内核线程被CPU中断处理,进程内的其他线程可以重新与其他内核线程绑定。
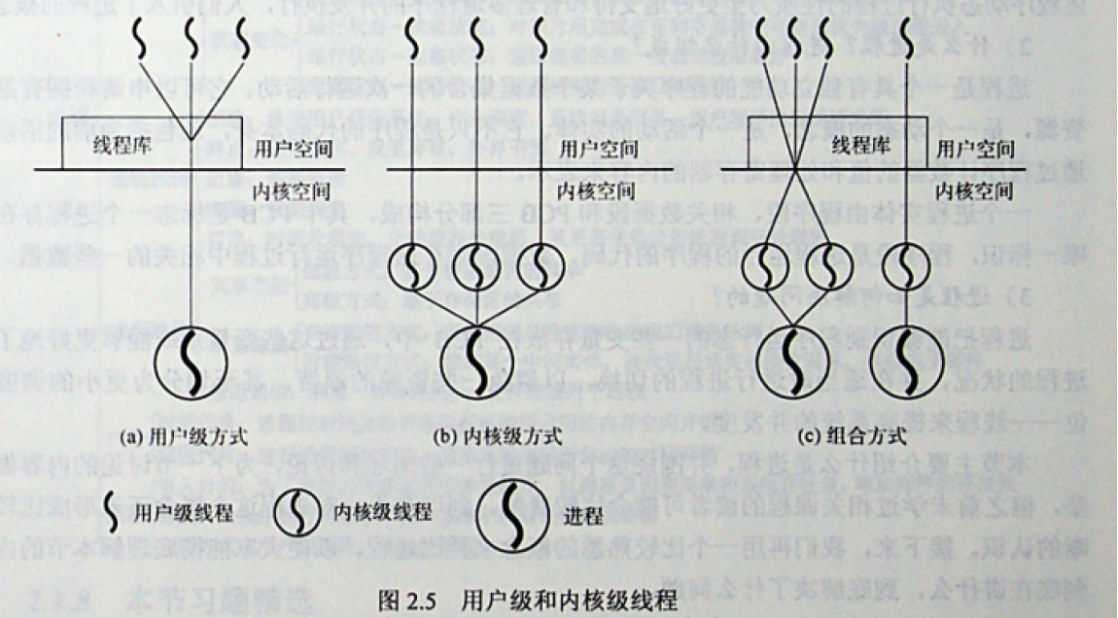
goroutine使用的正是两级线程模型,但是这种多个线程跑在多个内核中,既不是用户级线程模型完全靠自身调度也不是内核级线程模型完全依赖内核调度,而是用户和内核协同调度。因为这种模型复杂性较高,所以Go语言开发了自己的runtime调度器。
三、Go runtime调度器
Go runtime调度器的结构由三部分组成:
- G
Goroutine,每个goroutine有对应的G结构体,G结构体储存goroutine的上下文信息。G并不能直接被调度,需要绑定对应的P才能被调度执行。 - P
Processor,为G和M进行调度的逻辑处理器,对于G来说P像是内核,而在M看来P相当于上下文。P的数量可以在程序中代码控制,如下:1
runtime.GOMAXPROCS(runtime.NumCPU()) // 该值最大为256。
- M
Machine,负责调度任务(可以理解为内核线程的抽象),代表着操作系统内核,是真正处理任务的服务。M的数量不是固定的,受Go runtime调度器控制。(不过该值最大为10000,可以参考:src/runtime/proc.go)
值得一提的是Go语言在最初的版本中Go runtime调度器的结构是GM模型(并非GMP模型),P服务是因为GM模型在并发上出现很大的性能损耗。有兴趣的小伙伴可以看一下Go runtime的核心开发者Dmitry Vyukov发现的问题Scalable Go Scheduler Design Doc。
简单说了一下Go runtime调度器中的GPM模型的概念,那么GPM究竟是怎么调度的呢?
首先当通过go func()创建一个G对象的时候,G会被优先放入P的本地队列。为了执行G M需要绑定一个P,然后M启动内核线程并循环从P的本地队列取出G并执行。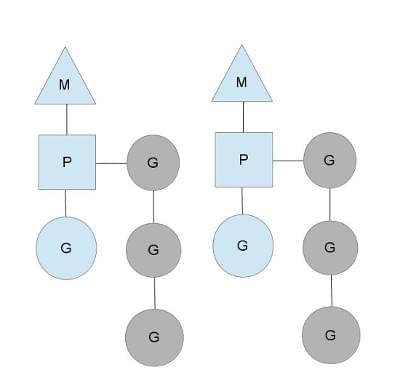
当P发现当前绑定的M被阻塞时会转入绑定其他M(新的M可能是被创建或者从内核线程缓存中取出)。
如果M处理完了当前P的本地队列里的G后,P会尝试从全局队列里取G来执行(同样P也会周期性的检查全局队列是否有G可以执行)。如果全局队列没有可以执行的G,P会随机挑选另外一个P并从它的本地队列中取出一半G到自己的本地队列中执行。这个动作使用调度算法work-stealing(工作窃取算法)实现。
最后
以上就是Go runtime调度器的运行原理(大概),后面有更深入的理解会补充进来。