ClickHouse 是这两年备受瞩目的开源列式数据库,主要应用场景是 OLAP(在线数据分析处理)场景。
背景
之前因为遇见一些小问题,所以想通过存储结构和索引方式两个方面搞清楚它为什么可以这么快。
ClickHouse 是 OLAP 型的列式数据库,官方称比较行式数据库查询效率提升至少 100 倍,DB Benchmark显示 ClickHouse 比 Mysql 快 800 倍!
什么是 OLAP 型列式数据库
OLAP 业务场景一般具有以下特征:
- 多数是查询请求,但请求不密集。
- 数据写入不频繁,或者单次大批量写入数据。
- 尽量不更新或少更新历史数据。
- 数据表列比较多(宽表),但每列存储数据较小。
- 对数据一致性要求较低,不依赖事务。
- 查询请求目标数据表比较独立,或者除目标表外其他需要关联的表的数据量相对很少。
- 查询结果集数据量远远小于源数据表,至少服务器内存不会溢出。
- 简单的查询,毫秒级别的响应。
- 单次查询高吞吐量。
列式和行式数据库的区别
存储方式
- 行式
| Row | WatchID | JavaEnable | Title | GoodEvent | EventTime |
|---|---|---|---|---|---|
| #0 | 89354350662 | 1 | Investor Relations | 1 | 2016-05-18 05:19:20 |
| #1 | 90329509958 | 0 | Contact us | 1 | 2016-05-18 08:10:20 |
| #2 | 89953706054 | 1 | Mission | 1 | 2016-05-18 07:38:00 |
| #N | … | … | … | … | … |
- 列式
| Row: | #0 | #1 | #2 | #N |
|---|---|---|---|---|
| WatchID: | 89354350662 | 90329509958 | 89953706054 | … |
| JavaEnable: | 1 | 0 | 1 | … |
| Title: | Investor Relations | Contact us | Mission | … |
| GoodEvent: | 1 | 1 | 1 | … |
| EventTime: | 2016-05-18 05:19:20 | 2016-05-18 08:10:20 | 2016-05-18 07:38:00 | … |
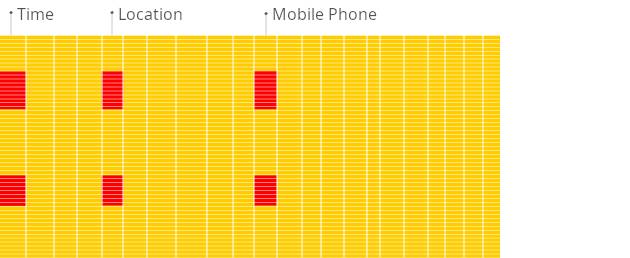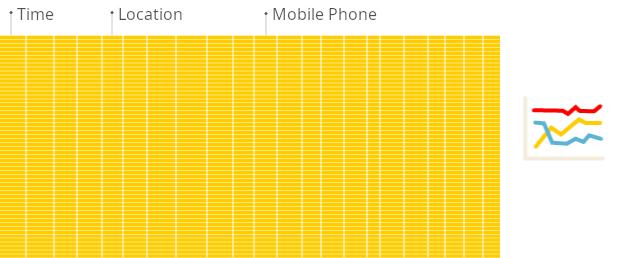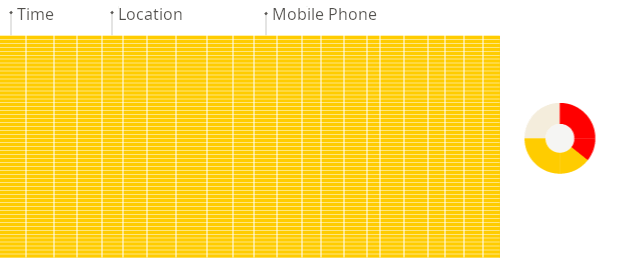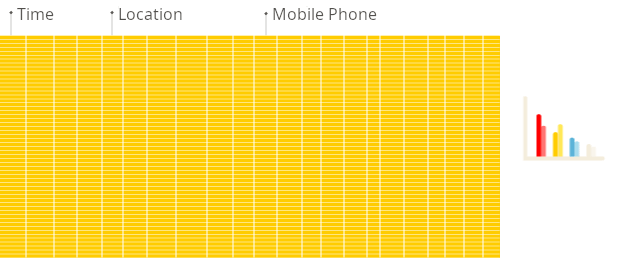
检索方式(通过两张图感受一下)
行式:
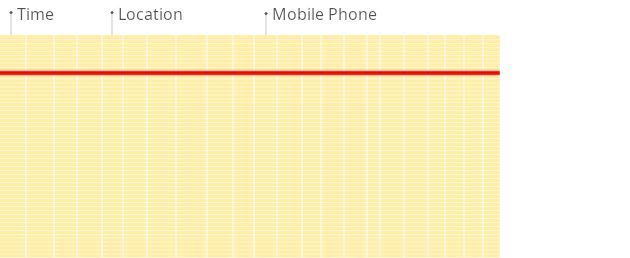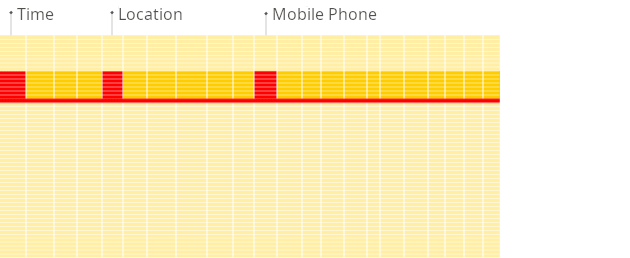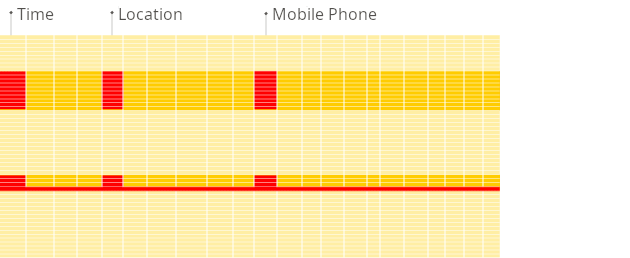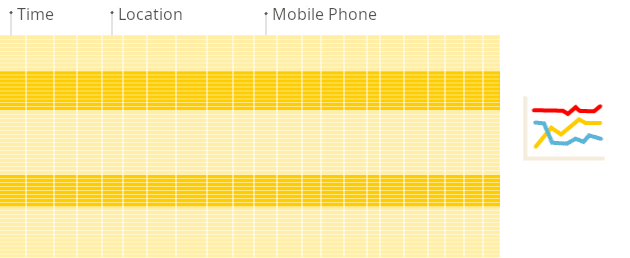
列式:
列式数据库的优势
- 查询请求时只读取需要的列,而不是像行式数据库需要读取符合条件的所有 block(即使是行式数据库也不是按行读取数据而是块,有些数据库也称页)。需要读取数据量的减少,意味着 IO 操作会更快。
- 同一列的数据类型一致,可以使用最适用的压缩算法(更高的压缩比),节省存储空间。
ClickHouse 的优缺点
- 优点
- 支持 SQL 语法,不像 ES 的 DSL 那样晦涩难懂。
- 可以保证数据一致性(最终)。
- 压榨性能极限,多核心处理使用机器一切可用资源。
- 高效的磁盘 IO,数据都是有序存储。
- 查询不需要遵守索引
最左原则。 - 批量写入速度快。
- 缺点
- 部分 SQL 语法不支持,但无伤大雅。
- 更新和删除操作支持不好。
- 不支持事务。
- 不支持高并发,官方默认 QPS:100(可以通过配置修改)
简单的列举了优缺点,这只是冰山一角。实际上 ClickHouse 值得深入探讨的太多太多。
MergeTree 的特性
ClickHouse 是真正的列式存储数据库,不同于内存计算引擎(比如 SparkSQL、Presto),它有自己的数据存储机制和索引方式。
1 | CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] |
ORDER BY
排序字段,数据存储时按照排序字段(排序字段可以是一个字段,也可以是元组)进行有序存储。
PARTITION BY
ClickHouse 支持按列值进行数据分区,也支持以表达式进行分区(比如
toYear(date)),分区字段值不可以过多,否则会报错(比如按照 user_id 分区)。主要作用是分区裁剪,过滤非必要的查询数据。PRIMARY KEY
ClickHouse 的 MergeTree 引擎可以定义主键,但不同于行式数据库。主键不做唯一约束,可以是多个字段。默认不定义主键,会将排序键作为主键。如果定义主键(排序键过大,为了控制主键文件大小),则尽量保证是排序键的前部分键。
SAMPLE BY
ClickHouse 提供的抽样表达式机制,查询请求时通过采样子句进行数据采样功能。
建表时需要声明采样表达式(通过哪个字段采样),该字段必须是UInt类型且必须出现在主键或排序键中(如果不是 UInt 类型可以声明,但使用会报错)。
1 | create table example |
查询请求时,通过
sample关键字进行伪随机数据采样。
1 | select * from example sample 1/10 # 数据的10% |
可以通过字段
_sample_factor查询采样系数,该字段是虚拟的。
- TTL
ClickHouse 原生支持的数据生命周期管理的机制,在 MergeTree 中可以为列、表 2 个级别设置 TTL,当时间到期后触发相应级别的数据删除操作。
无论是哪种级别的 TTL,字段必须为Datetime或Date类型,因为依赖 INTERVAL 设置生命周期。
1 | create table example |
- 当列级 TTL 触发时,会把对应值修改为列类型的默认值,如果该列数据全部过期则会
删除该列。- 当表级 TTL 触发时,会删除所有符合过期条件的数据行。
- 当同时设置列级、表级 TTL,以先到期的为准。
- SETTINGS
控制 MergeTree 行为的额外参数,可选项:
1 | index_granularity # 索引粒度。索引中相邻的『标记』间的数据行数。默认值8192 。 |
其他更多参数,可以查阅官方文档SETTINGS部分。
存储结构
使用 MergeTree 引擎,一张数据表会分成 N 个数据分区,每个数据分区对应一个文件目录。
可以通过 SQL 查询到分区信息:
1 | SELECT * FROM system.parts WHERE `table` = '{table}' -- path字段是数据分区的存储位置 |
或者在 ClickHouse 数据存储目录查看
1 | $ cd /data/clickhouse/data |
- 20220101_1_3_0
数据分区的名称,由 4 部分组成。
- 名称:20220101
- 最小数据块编号:1
- 最大数据块编号:3
- 数据块级别:0(即在由块组成的合并树中,该块在树中的深度)
checksums.txt
校验文件,使用二进制存储数据目录的文件信息,保证安全性和完整性。
columns.txt
明文存储列信息(列名,列类型)
{column}.bin
核心数据文件(二进制存储),分区字段
part_type为Wide时会为每列创建对应的数据文件,如果是Compact则所有列存储在一个数据文件。该值受配置min_bytes_for_wide_part、min_rows_for_wide_part影响。
该文件的内容以数据 Block 存储(也称页),数据是否压缩受配置max_compress_block_size、min_compress_block_size影响。默认压缩格式:lz4。
Block 数据块分为两部分:头信息和数据。头信息固定占 9 字节:压缩方式 1 字节、压缩后大小 4 字节、压缩前大小 4 字节。{column}.mrk
列字段标记文件(二进制存储),文件中记录{column}.bin 文件中数据 Block 的偏移量。
count.txt
该数据分区的数据行数。
primary.idx
主键索引文件(二进制存储),每
index_granularity行取主键值作为稀疏索引。partition.dat
当前数据分区的编号。
minmax_{column}.idx
列索引文件,存储列的最大值和最小值。
skpidx{column}.idx
跳数索引(又称二级索引)文件,受
allow_experimental_data_skipping_indices参数控制,默认不开启。skpidx{column}.mrk
跳数索引标记文件。
detached
执行
ALTER TABLE table_name DETACH PARTITION|PART partition_expr命令后,会将对应的数据分离至该目录并“遗忘”。format_version.txt
记录存储的格式。
mutation_{key}.txt
不同于行式数据库,ClickHouse 对于 mutation 操作(Update、Delete)是异步执行的,同时会生成
mutation_{key}.txt文件记录操作和生成新的数据目录20220101_1_3_0_{key}。可以通过 SQL 查询:
1 | SELECT * FROM system.mutations WHERE `table` = '{table}' |
因为使用类 LSM 架构,该类操作尽量少执行(埋个坑,后面再去研究)