AST(Abstract syntax tree)抽象语法树,用于表示编程语言源代码的一种抽象语法的结构,树的每个节点都对应源代码中的一个结构。
前言
计算机如何生成 AST 结构?一般来说顺序如下:
- 词法分析
扫描源代码,生成标记(token)
- 语法分析
解析 tokens,构造 AST 结构
分析过程:
AST 结构:
应用场景
AST 应用场景比较广泛,比如:
Typescript 编译 Javascript 文件
格式化插件
代码混淆/压缩
类型检查/推导
等等…诸多应用场景。
词法分析
如何读入源代码,扫描、解析以及生成 AST?下面尝试用一个可以计算+、-、*、/公式的小程序来学习和实验。
假设,给定的源码是1+2+3,应该怎样去扫描?扫描原理很简单,通俗的说就是按字符读取记录为 Token。
1 | // 首先定义存储标记的结构 |
以上,扫描工作就完成了!
但词法分析一般没有这么简单,比如数字1和操作符+也不应该是同一种类型。所以我们需要改造词法分析器!在生成 Token 的同时记录类型,方便进一步处理。这里我们使用状态机的设计思路:
- 读入一个字符
- 判断字符类型,数字 or 操作符
1. 是数字,记录当前字符位置,继续读取下一个字符,直至非数字或者字符边界,记录完整的数值。
2. 不是数字,直接记录操作符。 - 返回 token
详细扫描逻辑,如下:
1 | type Lexer struct { |
现在,我们调用词法分析器解析1+2+3
1 | lexer := lexer.Lexer{ |
语法分析
生成 tokens 是第一步,这一串 token 又要怎样去解析呢?
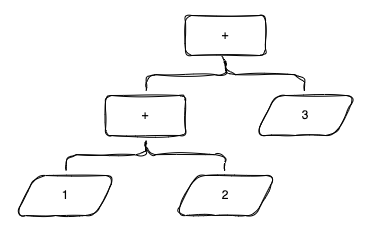
已知+-*/均属于二元运算,二元运算三元素:运算符、左变量、右变量。所以我们需要的结构大概是这样:Number{1} Op{+} Number{2} Op{+} Number{3},用二叉树来表示:
1 | // 首先定义一个语法分析器 |
处理逻辑如下:
- 顺序取出一个 token。
- ParseExpr()判定 token 类型,返回对应结构,下标+1(处理下一个 token,应当是运算符 token)。
1. 如果是数值类型,则直接返回 Number{}结构。
2. 如果是运算符类型,则递归处理返回 Stmt{}结构。 - ParseRight()处理右侧变量,把左侧变量传入函数。
- 根据运算符判断变量优先级问题,如果当前运算符小于传入变量优先级,则直接返回传入变量,处理结束。
- 记录当前运算符(类型),下标+1,处理当前操作符右侧变量(步骤 2)。
- 再次判断传入变量优先级是否低于当前运算符。
1. 是,则把右侧变量(步骤 4)当成左侧变量传入递归处理。
2. 不是,则构造二元运算表达式 Stmt{Type: 运算符类型, Left: 左侧变量, Right: 右侧变量}。 - 当前循环结束,回到步骤 4。
1 | func (r *Parser) Parse() (Node, error) { |
看看效果:
1 | lexer := lexer.Lexer{ |
最后
有了 AST 结构,我们就可以开始进行计算啦~这样一个支持+-*/的小程序就完成了!计算逻辑相对比较简单,这里直接贴代码:
1 | // 数值类型 |
附上完整代码:math-evaluate